- Требования к хранению данных
Тип хранилища (NVMe, SSD, объектное), объём и скорость доступа.
- Требования к отказоустойчивости
Допустимые простои, резервирование узлов и компонентов.
Планируемое расширение инфраструктуры в течение 1–3 лет.
Доступная мощность питания, охлаждение и физическое размещение оборудования.
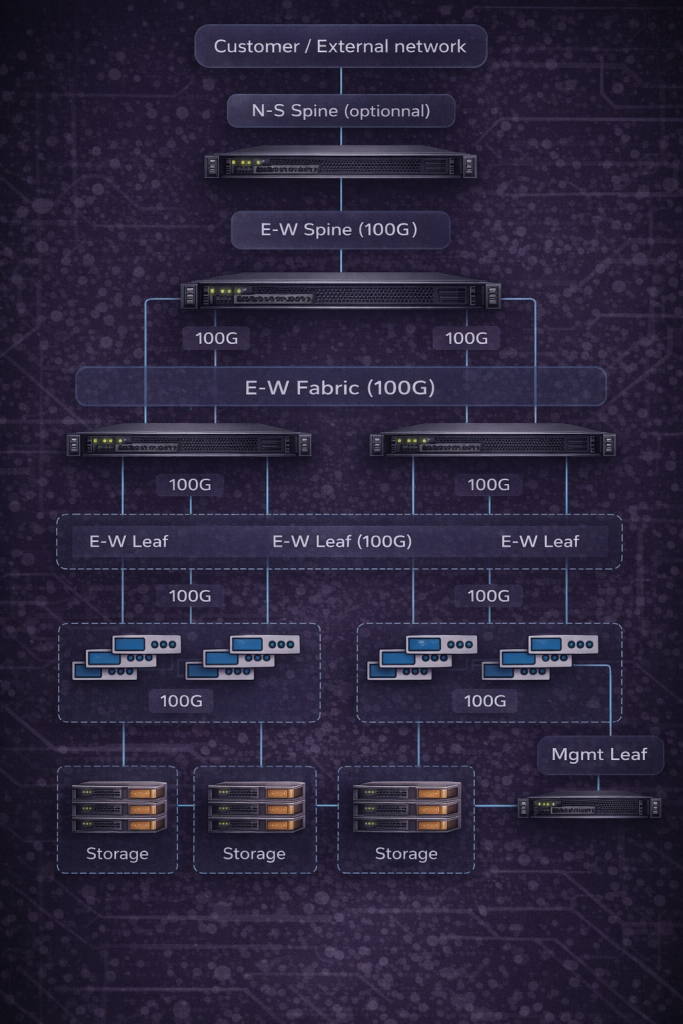
- Интеграция с существующей инфраструктурой
Текущие серверы, системы хранения, сеть и программные платформы.